Data Ingestion & Knowledge Sources
100+ document loaders – PDF, CSV, JSON, HTML, Markdown, Notion, Confluence, GitHub via codeCustom pipelines – Build proprietary ingestion for any data source with full control⚠️ Code-first only – No UI for data upload; requires Python/JS development
✅ Enterprise Integrations – APIs connect to Snowflake, Databricks, Salesforce, data lakes✅ High Volume Processing – Async APIs handle millions/billions of records efficientlyPII/PHI Scanning – Detects sensitive data across structured and unstructured sources⚠️ No File Uploads – Designed for data pipelines, not document upload workflows
1,400+ file formats – PDF, DOCX, Excel, PowerPoint, Markdown, HTML + auto-extraction from ZIP/RAR/7Z archivesWebsite crawling – Sitemap indexing with configurable depth for help docs, FAQs, and public contentMultimedia transcription – AI Vision, OCR, YouTube/Vimeo/podcast speech-to-text built-inCloud integrations – Google Drive, SharePoint, OneDrive, Dropbox, Notion with auto-syncKnowledge platforms – Zendesk, Freshdesk, HubSpot, Confluence, Shopify connectorsMassive scale – 60M words (Standard) / 300M words (Premium) per bot with no performance degradation
No built-in UI – Build your own with Streamlit, React, or custom frontendSlack/Discord examples – Community libraries available, but you handle coding⚠️ DIY deployment – All integrations require custom development
Security Middleware – API layer sanitizes data before reaching any LLM✅ Data Pipeline Integration – Works with Snowflake, Kafka, Databricks for AI workflows⚠️ No Chat Widgets – Backend security layer, not end-user interface platform
Website embedding – Lightweight JS widget or iframe with customizable positioningCMS plugins – WordPress, WIX, Webflow, Framer, SquareSpace native support5,000+ app ecosystem – Zapier connects CRMs, marketing, e-commerce toolsMCP Server – Integrate with Claude Desktop, Cursor, ChatGPT, WindsurfOpenAI SDK compatible – Drop-in replacement for OpenAI API endpointsLiveChat + Slack – Native chat widgets with human handoff capabilities
RAG chains – Retrieval-augmented QA combining LLMs with vector storesMulti-turn memory – Configurable conversation memory modulesTool-calling agents – External API and tool execution capabilities⚠️ No built-in citations – Manual implementation required for source links
⚠️ Not a Chatbot – Detects and masks sensitive data, doesn't generate responses✅ Advanced NER + Regex – Spots PII/PHI while preserving context and accuracyContent Moderation – Safety checks ensure compliance and prevent data exposure
✅ #1 accuracy – Median 5/5 in independent benchmarks, 10% lower hallucination than OpenAI✅ Source citations – Every response includes clickable links to original documents✅ 93% resolution rate – Handles queries autonomously, reducing human workload✅ 92 languages – Native multilingual support without per-language config✅ Lead capture – Built-in email collection, custom forms, real-time notifications✅ Human handoff – Escalation with full conversation context preserved
Total flexibility – Design any UI you want from scratch⚠️ No white-label features – No out-of-box branding tools⚠️ Extra development – Custom frontend required for any UI
⚠️ No Visual Branding – Backend middleware, no UI to customize or brand✅ Policy Customization – Tailor masking rules via dashboard or config filesCompliance-Focused – Configure policies to match GDPR, HIPAA, PCI DSS requirements
Full white-labeling included – Colors, logos, CSS, custom domains at no extra cost2-minute setup – No-code wizard with drag-and-drop interfacePersona customization – Control AI personality, tone, response style via pre-promptsVisual theme editor – Real-time preview of branding changesDomain allowlisting – Restrict embedding to approved sites only
Model-agnostic – OpenAI, Anthropic, Cohere, Hugging Face, local modelsAny vector DB – FAISS, Pinecone, Weaviate, Chroma, Qdrant supportedSelf-hosted option – Run Llama, Mistral locally for data privacyEasy switching – Change providers with minimal code changes
✅ Model-Agnostic – Works with any LLM: GPT, Claude, LLaMA, Gemini, custom models✅ LangChain Integration – Orchestrates multi-model workflows and complex AI pipelines✅ Context-Preserving – Maintains 99% accuracy (RARI) despite masking sensitive data
GPT-5.1 models – Latest thinking models (Optimal & Smart variants)GPT-4 series – GPT-4, GPT-4 Turbo, GPT-4o availableClaude 4.5 – Anthropic's Opus available for EnterpriseAuto model routing – Balances cost/performance automaticallyZero API key management – All models managed behind the scenes
Developer Experience ( A P I & S D Ks)
Python & JS libraries – Import directly, no hosted REST APILargest LLM community – 100K+ GitHub stars, 50K+ Discord membersExtensive docs – Tutorials, API reference, community plugins⚠️ Programming required – No no-code or low-code options
✅ REST APIs + Python SDK – Straightforward scanning, masking, and tokenizing implementationDetailed Documentation – Step-by-step guides for data pipelines and AI appsReal-Time + Batch – Supports ETL, CI/CD pipelines with comprehensive examples
REST API – Full-featured for agents, projects, data ingestion, chat queriesPython SDK – Open-source customgpt-client with full API coveragePostman collections – Pre-built requests for rapid prototypingWebhooks – Real-time event notifications for conversations and leadsOpenAI compatible – Use existing OpenAI SDK code with minimal changes
You control quality – Accuracy depends on LLM and prompt tuningDIY optimization – Response speed depends on your infrastructure⚠️ No built-in benchmarks – Test and optimize yourself
✅ 99% RARI Accuracy – Context-preserving masking vs 70% vanilla masking accuracy✅ Low Latency – Async APIs and auto-scaling maintain performance at high volumeSemantic Preservation – Masked data retains context for accurate LLM responses
Sub-second responses – Optimized RAG with vector search and multi-layer cachingBenchmark-proven – 13% higher accuracy, 34% faster than OpenAI Assistants APIAnti-hallucination tech – Responses grounded only in your provided contentOpenGraph citations – Rich visual cards with titles, descriptions, images99.9% uptime – Auto-scaling infrastructure handles traffic spikes
On-premise deployment – Run in your VPC for data sovereigntySelf-hosted models – Llama, Mistral via Ollama for full privacy⚠️ DIY security – No built-in encryption, auth, or compliance⚠️ No SLA – Open-source means no uptime guarantees
✅ GDPR/HIPAA/PCI DSS: Pre-configured policies, BAA support, Safe Harbor PHI maskingPDPL/DPDP Compliance: Saudi Arabia PDPL, India DPDP with regional policies✅ End-to-End Encryption: TLS in transit, encryption at rest with audit logs✅ Role-Based Access: Privileged users see unmasked data, others see tokens✅ Deployment Flexibility: SaaS, VPC, on-prem for strict data residencyZero Data Egress: On-prem ensures data never leaves organizational boundaries
SOC 2 Type II + GDPR – Regular third-party audits, full EU compliance256-bit AES encryption – Data at rest; SSL/TLS in transitSSO + 2FA + RBAC – Enterprise access controls with role-based permissionsData isolation – Never trains on customer dataDomain allowlisting – Restrict chatbot to approved domains
Framework: FREE – MIT license, unlimited commercial useLangSmith Dev: Free – 5K traces/month for debuggingLangSmith Plus: $39/seat/mo – Team collaboration, 10K traces⚠️ Hidden costs – LLM APIs + vector DB + hosting + dev time
Enterprise Pricing: Custom quotes based on volume, throughput, deployment model✅ Free Trial: Test platform capabilities before commitment with hands-on evaluationVolume Discounts: Pricing scales with usage, better rates for higher volumesCost Justification: Prevents regulatory fines (GDPR €20M, HIPAA $1.5M penalties)⚠️ No Public Pricing: Contact sales for custom quotes tailored to needs
Standard: $99/mo – 10 chatbots, 60M words, 5K items/botPremium: $449/mo – 100 chatbots, 300M words, 20K items/botEnterprise: Custom – SSO, dedicated support, custom SLAs7-day free trial – Full Standard access, no chargesFlat-rate pricing – No per-query charges, no hidden costs
Observability & Monitoring
LangSmith – Debugging and tracing for agent workflows⚠️ No native dashboard – Requires LangSmith subscription or DIY
Comprehensive Audit Logs – Tracks every masking action and sensitive data detection✅ SIEM Integration – Real-time compliance and performance monitoring with alertingRARI Metrics – Reports accuracy preservation and data protection effectiveness
Real-time dashboard – Query volumes, token usage, response timesCustomer Intelligence – User behavior patterns, popular queries, knowledge gapsConversation analytics – Full transcripts, resolution rates, common questionsExport capabilities – API export to BI tools and data warehouses
Active community – Discord, GitHub, Stack Overflow support700+ integrations – Community-contributed plugins and tools⚠️ No enterprise SLA – Community support only for free tier
✅ Enterprise Support – Dedicated account managers and SLA-backed assistanceRich Documentation – API guides, whitepapers, and secure AI pipeline best practicesIndustry Partnerships – Active thought leadership and compliance standards collaboration
Comprehensive docs – Tutorials, cookbooks, API referencesEmail + in-app support – Under 24hr response timePremium support – Dedicated account managers for Premium/EnterpriseOpen-source SDK – Python SDK, Postman, GitHub examples5,000+ Zapier apps – CRMs, e-commerce, marketing integrations
Custom RAG apps – Enterprise knowledge bases with full controlMulti-step agents – Research, analysis, automation workflowsCode assistance – Generation, review, documentation tools⚠️ Weeks to deploy – Unlike 2-minute turnkey platforms
Healthcare AI: HIPAA-compliant patient analysis, clinical support, PHI masking in medical recordsFinancial Services: PCI DSS payment data compliance, financial records, customer service chatbotsGovernment & Defense: Classified data protection, citizen privacy, strict data residency requirementsCustomer Support: Secure analysis of tickets, emails, transcripts with PII for AI insightsMulti-Agent Workflows: Role-based data access across AI agents for global enterprisesClaims Processing: Insurance PHI protection for accurate, privacy-preserving RAG workflows
Customer support – 24/7 AI handling common queries with citationsInternal knowledge – HR policies, onboarding, technical docsSales enablement – Product info, lead qualification, educationDocumentation – Help centers, FAQs with auto-crawlingE-commerce – Product recommendations, order assistance
Limitations & Considerations
⚠️ Programming mandatory – Python/JS skills required⚠️ Weeks-months to production – Not rapid deployment⚠️ DIY everything – Security, UI, monitoring, compliance⚠️ Breaking changes – Frequent API updates require maintenance⚠️ Hidden infrastructure costs – LLM + DB + hosting adds upIdeal for: Teams with ML engineers wanting maximum control
⚠️ NOT A RAG PLATFORM: Requires separate RAG/LLM infrastructure for complete solution⚠️ NO Chat UI: Technical dashboard only, not end-user chatbot interface⚠️ Developer Integration Required: APIs/SDKs need coding expertise for pipeline integrationHigher Cost: Enterprise pricing but prevents GDPR €20M, HIPAA $1.5M finesPerformance Overhead: Real-time masking adds sub-second latency in high-throughput systemsBest For: Regulated industries (healthcare, finance, government) requiring compliance, not general-purpose
Managed service – Less control over RAG pipeline vs build-your-ownModel selection – OpenAI + Anthropic only; no Cohere, AI21, open-sourceReal-time data – Requires re-indexing; not ideal for live inventory/pricesEnterprise features – Custom SSO only on Enterprise plan
LangGraph – Low-level agentic framework launched 2024Tool calling – Agents autonomously invoke APIs and functionsMulti-step workflows – Average 7.7 steps per trace in 2024Custom architectures – Build specialized agent systems
✅ Multi-Agent Access Control: Fine-grained identity-based access enforcement across agentic workflows✅ Role-Based Security: Controls who sees what at inference time with role-specific permissionsLangChain/CrewAI Integration: Comprehensive agentic workflow protection with major orchestration frameworksAgent Context Sanitization: Masks PII/PHI in prompts, context, and responses during multi-step reasoningSecRAG for Agents: RBAC integrated into retrieval, checks authorization before agent access⚠️ NOT Agent Orchestration: Secures workflows but requires LangChain/CrewAI for coordination
Custom AI Agents – Autonomous GPT-4/Claude agents for business tasksMulti-Agent Systems – Specialized agents for support, sales, knowledgeMemory & Context – Persistent conversation history across sessionsTool Integration – Webhooks + 5,000 Zapier apps for automationContinuous Learning – Auto re-indexing without manual retraining
Full RAG toolkit – Loaders, splitters, embeddings, retrievers, chains100+ vector stores – Pinecone, Chroma, Weaviate, FAISS, MilvusHybrid search – Combine vector + keyword (BM25) retrievalReranking – Cohere Rerank, cross-encoder models supported
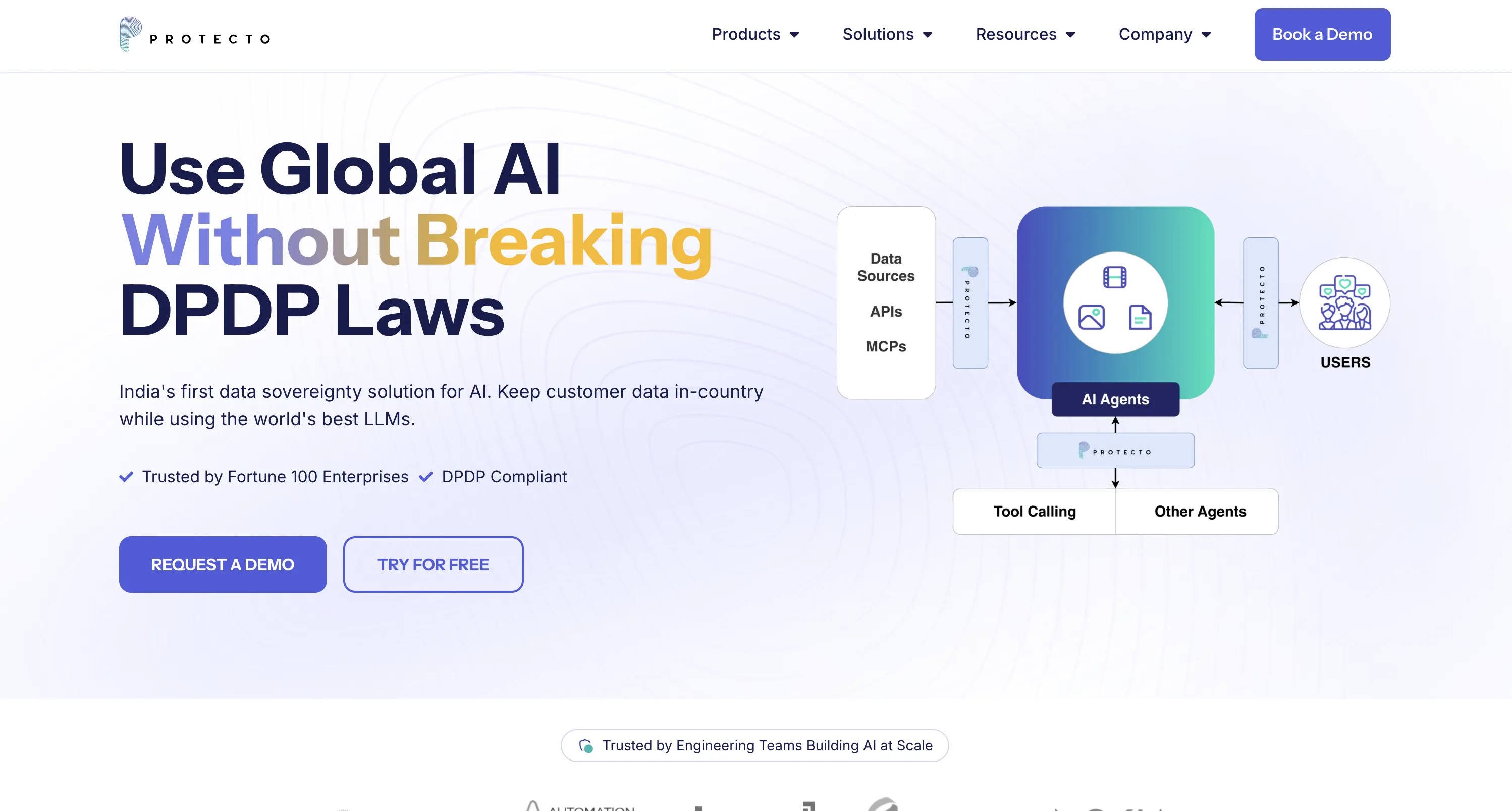
⚠️ NOT A RAG PLATFORM: Security middleware only, not retrieval-augmented generation platformRAG Protection Layer: Masks PII/PHI before RAG indexing and vector database storage✅ Real-Time Sanitization: Intercepts data to/from RAG systems preventing sensitive data leakage✅ Context Preservation: Maintains semantic meaning for accurate RAG retrieval despite maskingQuery + Response Security: Masks sensitive data in queries and post-processes responsesIntegration Point: Security middleware between data sources and RAG platforms
GPT-4 + RAG – Outperforms OpenAI in independent benchmarksAnti-hallucination – Responses grounded in your content onlyAutomatic citations – Clickable source links in every responseSub-second latency – Optimized vector search and cachingScale to 300M words – No performance degradation at scale
Market position – Leading open-source LLM framework, largest developer communityTarget users – Developers/ML engineers wanting maximum flexibilityvs CustomGPT – Weeks of coding vs 2-minute deployment; full control vs managed servicevs Haystack/LlamaIndex – Larger community, more integrationsNOT for: Non-technical users, rapid deployment, teams without ML expertise
Market position: Enterprise data security middleware for AI, not RAG platformTarget customers: Healthcare, finance, government needing GDPR/HIPAA/PCI compliance and on-prem deploymentKey competitors: Presidio (Microsoft), Private AI, Nightfall AI, traditional DLP tools✅ Competitive advantages: 99% RARI vs 70% vanilla, handles billions of recordsPricing advantage: Higher cost but prevents regulatory fines (GDPR €20M, HIPAA $1.5M)Use case fit: Critical for healthcare PII/PHI, financial records, government data compliance
Market position – Leading RAG platform balancing enterprise accuracy with no-code usability. Trusted by 6,000+ orgs including Adobe, MIT, Dropbox.Key differentiators – #1 benchmarked accuracy • 1,400+ formats • Full white-labeling included • Flat-rate pricingvs OpenAI – 10% lower hallucination, 13% higher accuracy, 34% fastervs Botsonic/Chatbase – More file formats, source citations, no hidden costsvs LangChain – Production-ready in 2 min vs weeks of development
R A G-as-a- Service Assessment
Platform type – FRAMEWORK, NOT RAG-AS-A-SERVICEDIY architecture – Build entire pipeline from scratch with codeNo managed infrastructure – You host vector DB, LLM, serversBest for: Teams building custom RAG with full controlAlternative: For managed RaaS, use CustomGPT, Vectara, or Azure AI
⚠️ NOT RAG-AS-A-SERVICE: Data security middleware, not retrieval-augmented generation platformSecurity Middleware: Sits between data sources and RAG platforms as protection layerRAG Protection: Sanitizes documents before indexing, queries before retrieval, responses before delivery✅ Context-Preserving RAG: 99% RARI vs 70% vanilla masking for accurate retrievalStack Position: Protecto (security) + CustomGPT/Vectara (RAG) + OpenAI (LLM) = complete solutionBest Comparison: Compare to Presidio, Private AI, Nightfall AI, not RAG platforms
Platform type – TRUE RAG-AS-A-SERVICE with managed infrastructureAPI-first – REST API, Python SDK, OpenAI compatibility, MCP ServerNo-code option – 2-minute wizard deployment for non-developersHybrid positioning – Serves both dev teams (APIs) and business users (no-code)Enterprise ready – SOC 2 Type II, GDPR, WCAG 2.0, flat-rate pricing
OpenAI – GPT-4, GPT-4 Turbo, GPT-3.5 with full controlAnthropic – Claude 3 Opus/Sonnet with 200K contextHugging Face – 100K+ models including Llama, Mistral, FalconSelf-hosted – Ollama, GPT4All for complete privacy
✅ Model-Agnostic: Works with GPT-4, Claude, LLaMA, Gemini, custom modelsPre-Processing Layer: Masks data before LLM access, not tied to providers✅ LangChain Integration: Orchestrates multi-model workflows and complex AI pipelines✅ Context-Preserving: 99% RARI vs 70% vanilla masking accuracyNo Lock-In: Switch LLM providers without changing Protecto configuration
OpenAI – GPT-5.1 (Optimal/Smart), GPT-4 seriesAnthropic – Claude 4.5 Opus/Sonnet (Enterprise)Auto-routing – Intelligent model selection for cost/performanceManaged – No API keys or fine-tuning required
No- Code Interface & Usability
No no-code interface – Developer-only frameworkCommunity wrappers – Streamlit, Gradio for basic UIs⚠️ Custom dev required – Full end-to-end UX needs coding
⚠️ No Chatbot Builder – Technical dashboard for policy setup, not end-user interfaceIT/Security Focus – Config panels for technical teams, not wizard-style tools✅ Guided Presets – HIPAA Mode, GDPR Mode for rapid compliance onboarding
2-minute deployment – Fastest time-to-value in the industryWizard interface – Step-by-step with visual previewsDrag-and-drop – Upload files, paste URLs, connect cloud storageIn-browser testing – Test before deploying to productionZero learning curve – Productive on day one
Customization & Flexibility ( Behavior & Knowledge)
Full control – Prompts, retrieval, chains, agents customizableCustom logic – Add any behavioral rules or decision patternsMix data sources – Combine multiple knowledge bases on the fly
✅ Custom Regex Rules – Fine-tune masking with granular entity types and patterns✅ Role-Based Access – Privileged users see unmasked data, others see tokensDynamic Policies – Update masking rules without model retraining for new regulations
Live content updates – Add/remove content with automatic re-indexingSystem prompts – Shape agent behavior and voice through instructionsMulti-agent support – Different bots for different teamsSmart defaults – No ML expertise required for custom behavior
Framework: Free – MIT license, no usage limitsDIY scaling – Manage hosting, vector DB growth, optimization⚠️ Total cost – LLM APIs + infra + dev time often exceeds managed platforms
Enterprise Pricing – Custom quotes based on data volume and throughput✅ Massive Scale – Handles millions/billions of records, cloud or on-prem deploymentVolume Discounts – Free trial available, pricing optimized for large organizations
Standard: $99/mo – 60M words, 10 botsPremium: $449/mo – 300M words, 100 botsAuto-scaling – Managed cloud scales with demandFlat rates – No per-query charges
Official docs – python.langchain.com with tutorials, API referenceCommunity – 50K+ Discord, 7K+ GitHub discussions⚠️ Doc quality mixed – Some gaps, rapidly changing APIs
✅ Enterprise Support: Dedicated account managers, SLA-backed assistance for large deploymentsComprehensive Docs: REST API, Python SDK, integration guides for data pipelinesWhitepapers & Best Practices: Security frameworks, compliance guides, AI pipeline architecturesIntegration Guides: Snowflake, Databricks, Kafka, LangChain, CrewAI, model gatewaysProfessional Services: Implementation help, custom policy setup, security workflow design✅ Training Resources: HIPAA Mode, GDPR Mode presets for rapid deployment
Documentation hub – Docs, tutorials, API referencesSupport channels – Email, in-app chat, dedicated managers (Premium+)Open-source – Python SDK, Postman, GitHub examplesCommunity – User community + 5,000 Zapier integrations
Additional Considerations
Significant engineering investment – Weeks to months for productionHidden costs – Infrastructure often exceeds managed platform feesBreaking changes – Frequent updates require code maintenanceIdeal for: Teams with dedicated ML engineers
✅ Secure RAG Focus – Protects sensitive data in third-party LLMs while preserving context✅ On-Prem Deployment – Total isolation for highly regulated sectorsProprietary RARI Metric – Proves aggressive masking maintains 99% model accuracy
Time-to-value – 2-minute deployment vs weeks with DIYAlways current – Auto-updates to latest GPT modelsProven scale – 6,000+ organizations, millions of queriesMulti-LLM – OpenAI + Claude reduces vendor lock-in
N/A
✅ Privacy-First – Masks PII/PHI before LLM access, meets GDPR/HIPAA/PCI DSS✅ End-to-End Encryption – TLS in transit, encryption at rest with audit logs✅ Deployment Flexibility – Public cloud, private cloud, or on-prem for data residency
SOC 2 Type II + GDPR – Third-party audited complianceEncryption – 256-bit AES at rest, SSL/TLS in transitAccess controls – RBAC, 2FA, SSO, domain allowlistingData isolation – Never trains on your data


Join the Discussion
Loading comments...